
Client Go 交互式编程
1、Client 客户端
client-go 支持 4 种 Client 客户端对象与 Kubernetes API Server 交互的方式(ClientSet、DynamicClient、DiscoveryClient、RESTClient),前三个都是基于 RestClient 做的二次封装。
1.1 kubeconfig
改文件中存储了集群、用户、命名空间和身份验证等信息,在默认的情况下,存放在 $HOME/.kube/config 路径下。其用于管理访问 kube-apiserver 的配置信息,同时也支持访问多 kube-apiserver 的配置管理,可以在不同的环境下管理不同的集群配置,不同的业务线也可以拥有不同的集群。
文件中主要定义三种信息:
clusters:定义 Kubernetes 集群信息,例如 kube-apiserver 的服务地址及集群的证书信息等;
users:定义 Kubernetes 集群用户身份验证的客户端凭据,例如 client-certificate、client-key、token 及 username/password 等;
contexts:定义 Kubernetes 集群用户信息和命名空间等,用于将请求发送到指定的集群。
其中还有一个字段,current-context 表示当前所使用的上下文,以此来划分多集群。
config, err := clientcmd.BuildConfigFromFlags("", clientcmd.RecommendedHomeFile)在实际使用中,通过 BuildConfigFromFlags 方法加载 config 文件,实例化为 rest.Config 对象。其中最核心的功能是管理多个访问 kube-apiserver 集群的配置信息,将多个配置信息合并(merge)成一份,在合并的过程中会解决多个配置文件字段冲突的问题。
if len(rules.ExplicitPath) > 0 {
if _, err := os.Stat(rules.ExplicitPath); os.IsNotExist(err) {
return nil, err
}
kubeConfigFiles = append(kubeConfigFiles, rules.ExplicitPath)
} else {
kubeConfigFiles = append(kubeConfigFiles, rules.Precedence...)
}可以通过两种方式获取配置文件:
文件路径(即rules.ExplicitPath);
环境变量(通过KUBECONFIG变量,即rules.Precedence,可指定多个路径)。
最后通过文件路径加载文件,并反序列化为 Config 对象,给后续客户端创建使用。
1.2 RESTClient
RESTClient 对 HTTP Request 进行了封装,实现了 RESTful 风格的 API。它具有很高的灵活性,数据不依赖于方法和资源,因此 RESTClient 能够处理多种类型的调用,返回不同的数据格式。
通过以下几步可以创建一个客户端来使用:
加载 kubeconfig 文件;
设置 config.APIPath 路径;
设置 config.GroupVersion 资源版本;
设置 config.NegotiatedSerializer 编解码器;
实例化 rest.RESTClientFor 客户端对象;
构建执行请求,执行命令。
请求发送之前需要通过 r.URL.String 函数拼接请求参数生成请求的 RESTful URL,最后通过 Go 语言标准库 net/http 向 kube-apiserver 发送请求,得到的结果通过 fn 函数(即transformResponse)转换为资源对象。
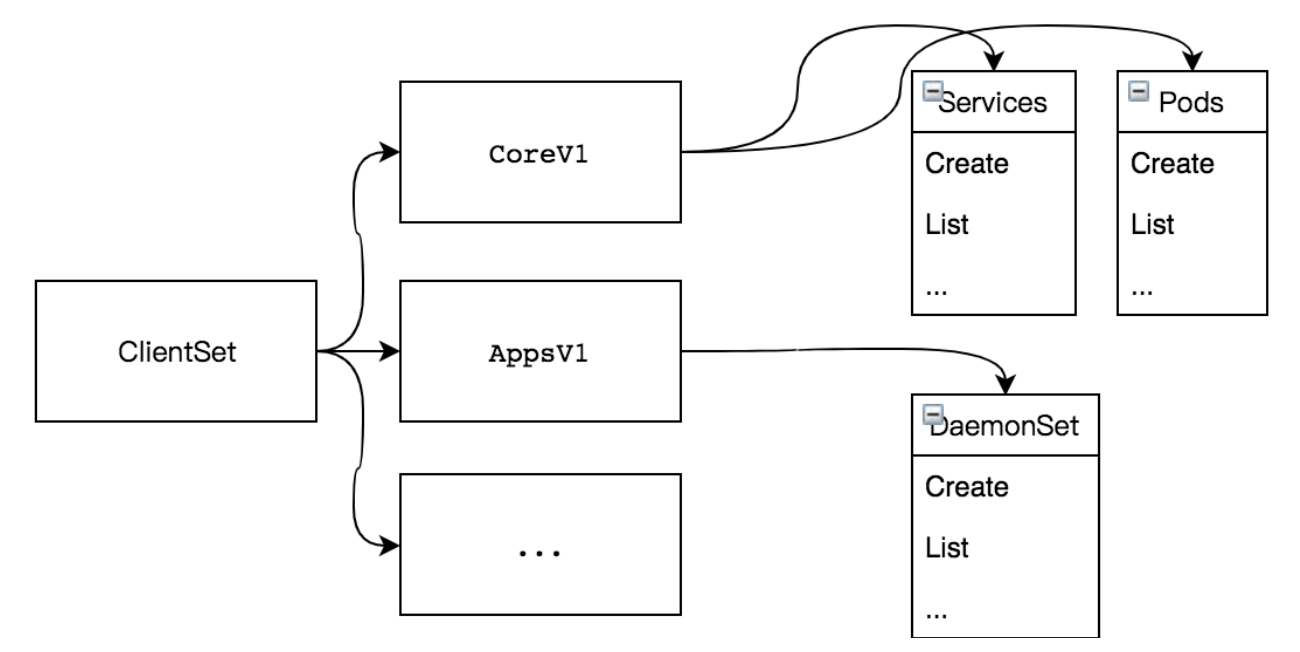
1.3 ClientSet
ClientSet 在 RESTClient 的基础上封装了对内置 Resource 和 Version 的管理方法,每一个 Resource 和 Version 都以函数的方式暴露给开发者,例如,ClientSet 提供的 RbacV1、CoreV1、NetworkingV1 等接口函数。
1.4 DynamicClient
DynamicClient 是一种动态客户端,它可以对任意 Kubernetes 资源进行 RESTful 操作,包括 CRD 自定义资源。与 ClientSet 操作类似,但是对于资源的访问层面还存在差异,其内部实现了 Unstructured,用于处理非结构化数据结构,从而能够访问 CRD 资源。
dynamicClient, err := dynamic.NewForConfig(config)
if err != nil {
log.Fatalln(err)
}
gvr := schema.GroupVersionResource{Version: "v1", Resource: "pods"}
dynamicClient.Resource(gvr).Namespace(corev1.NamespaceDefault).List(nil, metav1.ListOptions{Limit: 400})1.5 DiscoveryClient
DiscoveryClient 是发现客户端,它主要用于发现 Kubernetes API Server 所支持的资源组、资源版本、资源信息,并且可以将这些信息存储到本地,用于本地缓存(Cache),以减轻对 Kubernetes API Server 访问的压力(缓存信息默认存储于~/.kube/cache和~/.kube/http-cache)。
存在缓存,则有缓存失效的时间, 默认每10分 钟与 Kubernetes API Server 同步一次,缓存未命中的情况下直接请求服务,并存储缓存。
2、Informer
组件之间通过 HTTP 协议进行通信,在不依赖任何中间件的情况下需要通过 Informer 机制保证消息的实时性、可靠性、顺序性等。
2.1 架构设计

Reflector:监控(Watch)指定的 Kubernetes 资源,当监控的资源发生变化时,触发相应的变更事件。例如Added(资源添加)事件、Updated(资源更新)事件、Deleted(资源删除)事件,并将其资源对象存放到本地缓存 DeltaFIFO 中。
DeltaFIFO:FIFO 是一个先进先出的队列,而 Delta 是一个资源对象存储,它可以保存资源对象的操作类型。
Indexer:是用来存储资源对象并自带索引功能的本地存储,Reflector 从 DeltaFIFO 中将消费出来的资源对象存储至 Indexer,数据与 Etcd 中完全保持一致。方便从本地存储中读取相应的资源对象数据,而无须每次从远程 Etcd 集群中读取,以减轻 Kubernetes API Server 和 Etcd 集群的压力。
2.2 代码样例
c := make(chan struct{})
defer close(c)
// clientset是用于与Kubernetes API Server交互的客户端,time.Minute用于设置多久进行一次resync(重新同步),周期性地执行List操作,将所有的资源存放在Informer Store中,如果该参数为0,则禁用resync功能
informerFactory := informers.NewSharedInformerFactory(client, time.Minute)
// 得到具体Pod资源的informer对象
informer := informerFactory.Core().V1().Pods().Informer()
//
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
},
UpdateFunc: func(oldObj, newObj interface{}) {
},
DeleteFunc: func(obj interface{}) {
},
})
informer.Run(c)添加资源事件回调方法,支持3种资源事件回调方法:
AddFunc:当创建Pod资源对象时触发的事件回调方法;
UpdateFunc:当更新Pod资源对象时触发的事件回调方法;
DeleteFunc:当删除Pod资源对象时触发的事件回调方法。
上面是针对于 pod 的监听回调,在 kubernetes 中每个资源都实现了 Informer 机制(实现 Informer 和 Lister 方法),因此所有资源都可以进行监听处理。
3、Reflector
Reflector 通过 ListerWatcher 入参来监听资源对象,其包含 List 和 Watch 两种方法,前者用于获取资源列表,后者则用于监控资源。
3.1 获取资源列表
在启动时获取该资源下所有的对象数据并将其存储至 DeltaFIFO 中,整个过程分为五个步骤执行:
获取资源
list, paginatedResult, err = pager.List(context.Background(), options)在这里传递了一个 options 参数,参数中 ResourceVersion 为 0 则表示获取所有的版本资源,为空则表示最新同步版本不可用,需要重新同步资源 Etcd 资源版本,否则获取特定的版本资源。
获取版本
listMetaInterface, err := meta.ListAccessor(list) resourceVersion = listMetaInterface.GetResourceVersion()每次修改当前资源对象时,Kubernetes API Server 都会更改 ResourceVersion,使得 client-go 执行 Watch 操作时可以根据 ResourceVersion 来确定当前资源对象是否发生变化。
资源转换
items, err := meta.ExtractList(list)将 runtime.Object 对象转换成 []runtime.Object 对象。因为获取的是资源下的所有对象的数据,例如所有的 Pod 资源数据,所以它是一个资源列表,需要进行转换使用。
本地存储
if err := r.syncWith(items, resourceVersion); err != nil { return fmt.Errorf("unable to sync list result: %v", err) }将资源对象列表中的资源对象和资源版本号存储至 DeltaFIFO 中,并会替换已存在的对象。
更新版本
r.setLastSyncResourceVersion(resourceVersion)
3.2 监控资源
Watch 使用 HTTP 协议的分块传输编码(Chunked Transfer Encoding),并与 Kubernetes API Server 建立长连接,当 client-go 调用 API Server 时,API Server 在 Response 的 HTTP Header 中设置 Transfer-Encoding 的值为 chunked,表示采用分块传输编码,客户端收到该信息后,便与服务端进行连接,并等待下一个数据块。
4、DeltaFIFO
type DeltaFIFO struct {
// lock/cond protects access to 'items' and 'queue'.
lock sync.RWMutex
cond sync.Cond
// Deltas 是一个 Delta 数组,其包含了对象信息
items map[string]Deltas
queue []string
}其本质上是一个先进先出的队列,有数据的生产者和消费者,其中生产者是 Reflector,通过调用 Add 方法注入数据,消费者是 Controller,通过调用 Pop 方法取出数据处理。
4.1 生产者
在 Added(资源添加)事件、Updated(资源更新)事件、Deleted(资源删除)事件中都调用了 queueActionLocked 方法,该方法实现就是往队列增加数据的。
func (f *DeltaFIFO) queueActionLocked(actionType DeltaType, obj interface{}) error {
// 计算 queue key
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
// 分装 Delta 对象
newDeltas := append(f.items[id], Delta{actionType, obj})
// 去重处理
newDeltas = dedupDeltas(newDeltas)
if len(newDeltas) > 0 {
if _, exists := f.items[id]; !exists {
f.queue = append(f.queue, id)
}
f.items[id] = newDeltas
// 通知消费者解除阻塞
f.cond.Broadcast()
} else {
delete(f.items, id)
}
return nil
}4.2 消费者
通过传入一个处理方法,取出队列头部的对象进行处理。
func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) {
f.lock.Lock()
defer f.lock.Unlock()
for {
for len(f.queue) == 0 {
if f.closed {
return nil, ErrFIFOClosed
}
// 空队列,等待唤醒
f.cond.Wait()
}
// 取出头部对象 key
id := f.queue[0]
// 模拟队列出
f.queue = f.queue[1:]
if f.initialPopulationCount > 0 {
f.initialPopulationCount--
}
item, ok := f.items[id]
if !ok {
// Item may have been deleted subsequently.
continue
}
delete(f.items, id)
err := process(item)
if e, ok := err.(ErrRequeue); ok {
f.addIfNotPresent(id, item)
err = e.Err
}
return item, err
}
}4.3 Resync
Resync 机制会将 Indexer 本地存储中的资源对象同步到 DeltaFIFO 中,并将这些资源对象设置为 Sync 的操作类型。
5、Indexer
Indexer是一个存储资源对象并自带索引功能的本地存储,数据与 Etcd 集群中的数据保持完全一致。client-go 可以很方便地从本地存储中读取相应的资源对象数据,而无须每次都从远程 Etcd 集群中读取,这样可以减轻 API Server 和 Etcd 集群的压力。
5.1 ThreadSafeMap
是一个内存中的存储,其每次的增、删、改、查操作都会加锁,以保证数据的一致性。将资源对象数据存储于一个 map 数据结构中,key 是 <namespace>/<name> 格式,如果没有命名空间,则是一个单独的 name,value 则是资源对象。
5.2 索引器
在每次增、删、改 ThreadSafeMap 数据时,都会通过 updateIndices 或 deleteFromIndices 函数变更 Indexer,其被设计为可以自定义索引函数,有 4 个非常重要的数据结构,分别是 Indices、Index、Indexers 及 IndexFunc。
Indexers:存储索引器,key 为索引器名称,value 为索引器的实现函数;
IndexFunc:索引器函数,接收一个资源对象,返回检索结果列表;
Indices:存储缓存器,key为缓存器名称,value为缓存数据。
Index:存储缓存数据,其结构为K/V。
6、WorkQueue
Kubernetes 的 WorkQueue 队列与普通 FIFO 队列相比,实现略显复杂,它的主要功能在于标记和去重:
去重:相同元素在同一时间不会被重复处理,不管一个元素在处理之前被添加了多少次,它只会被处理一次;
并发性:多个消费者和生产者,一般情况下都是单生产多消费;
标记机制:支持标记功能,标记一个元素是否被处理,也允许元素在处理时重新排队;
通知机制:ShutDown 方法通过信号量通知队列不再接收新的元素,并通知 metric goroutine 退出;
延迟:支持延迟队列,延迟一段时间后再将元素存入队列;
限速:支持限速队列,元素存入队列时进行速率限制。限制一个元素被重新排队(Reenqueued)的次数;
6.1 FIFO队列
FIFO 队列接口,先进先出队列,并支持去重机制,队列接收一个 Type 类型元素。
type Type struct {
queue []t
dirty set
processing set
}其中主要关注三个字段:
queue:存储队列,实际的数据存储;
dirty:也是一个存储队列,一般和 queue 保持一致,用于存储处理期间遇见其他的相同元素;
processing:正在处理的元素,当使用 get 从队列中取出头部元素后,从队列中删除,并且用该字段来记录当前处理的元素。
着重分析其去重能力,首先是取出队列执行操作的逻辑,从队列中取出头部元素,并且删除,之后将数据丢入 processing 中,最后元素丢给消费者去处理。
func (q *Type) Get() (item interface{}, shutdown bool) {
item, q.queue = q.queue[0], q.queue[1:]
q.processing.insert(item)
q.dirty.delete(item)
return item, false
}其次是添加队列执行操作的逻辑,如果已经在 dirty 中存在,则直接退出;如果正在 processing 中处理也直接退出。这里存在一个逻辑是正在处理的元素会先存入到 dirty 中,等到当前的元素被标记为 done 之后,才会从 dirty 挪回 queue 当中。
func (q *Type) Add(item interface{}) {
if q.dirty.has(item) {
return
}
q.dirty.insert(item)
if q.processing.has(item) {
return
}
q.queue = append(q.queue, item)
}6.2 延迟队列
基于 FIFO 队列接口封装,在原有功能上增加了 AddAfter 方法,其原理是延迟一段时间后再将元素插入 FIFO 队列。
6.3 限速队列
限速队列利用延迟队列的特性,延迟某个元素的插入时间,达到限速目的。
令牌桶算法
令牌桶算法内部实现了一个存放 token 的“桶”,初始时“桶”是空的,token 会以固定速率往“桶”里填充,直到将其填满为止,多余的 token 会被丢弃。每个元素都会从令牌桶得到一个 token,只有得到 token 的元素才允许通过,而没有得到token的元素处于等待。
排队指数算法
排队指数算法将相同元素的排队数作为指数,排队数增大,速率限制呈指数级增长,但其最大值不会超过 maxDelay,在一个限速周期内接收到的相同元素,会被指数时间延迟,其他的正常延迟。
计数器算法
限制一段时间内允许通过的元素数量,例如在1分钟内只允许通过100个元素,每插入一个元素,计数器自增1,当计数器数到100的阈值且还在限速周期内时,则不允许元素再通过。
7、EventBroadcaster
- 感谢你赐予我前进的力量
-
微信
- 支付宝









