Kubernetes 架构
本文最后更新于 2025-03-30,文章内容可能已经过时。
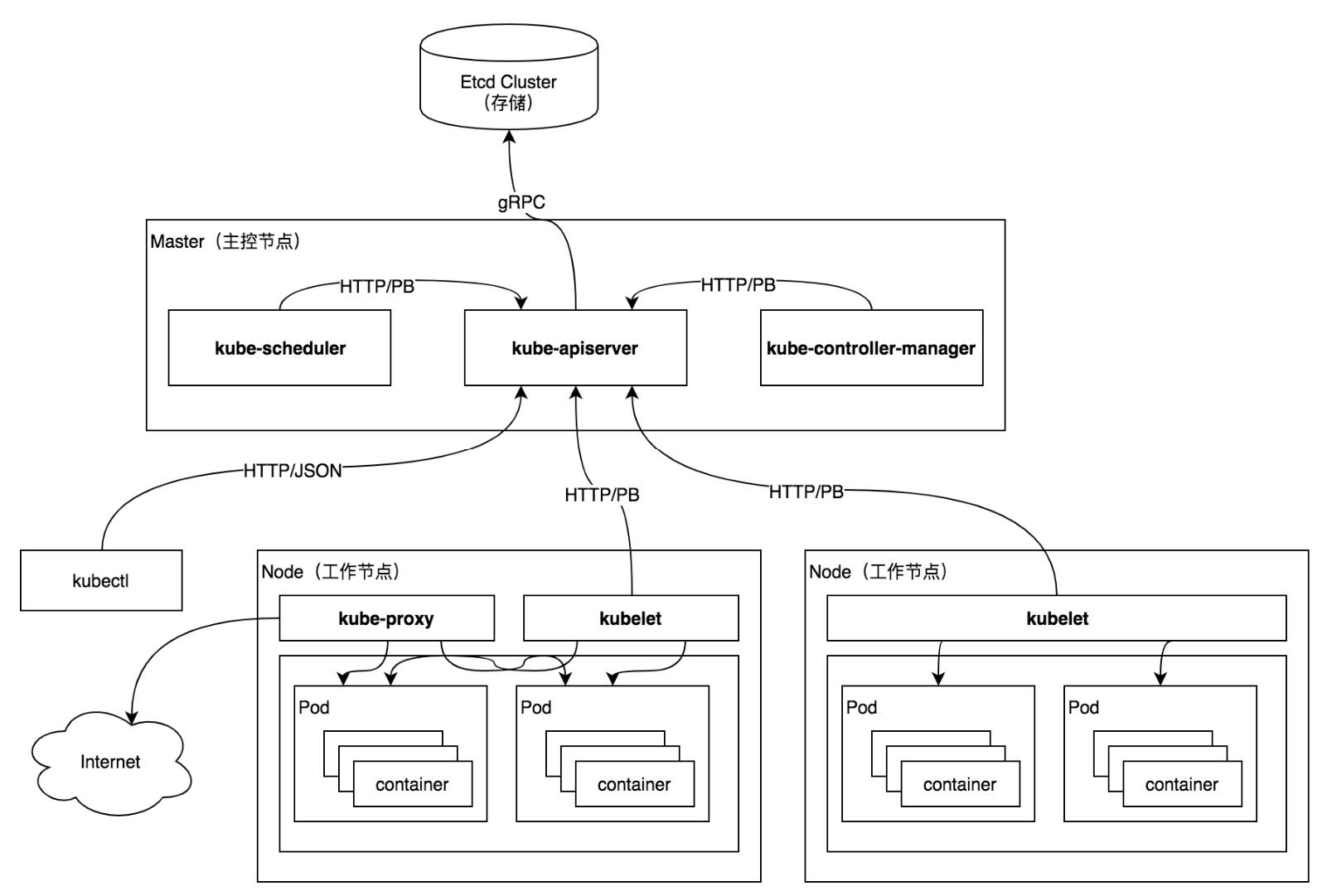
1、架构图
Kubernetes 系统架构遵循客户端/服务端(C/S)架构,系统架构分为 Master 和 Worker 两部分,Master 作为服务端,Worker 作为客户端。Kubernetes 系统具有多个 Master 服务端,可以实现高可用。
1.1 Master
Master 服务端也被称为主控节点,它在集群中主要负责如下任务:
集群的中枢,负责管理所有节点(Node);
负责计算并调度 Pod 在哪些节点上运行;
负责控制管理集群运行过程中的所有状态。
其中,主要包含三个组件:
kube-apiserver:负责将 Kubernetes
资源组/资源版本/资源以 RESTful 风格的形式对外暴露,提供了集群各组件的通信和交互功能,是唯一与 Etcd 数据直接交互组件。kube-controller-manager:负责管理 Kubernetes 集群中的节点、副本、服务、端点、命名空间、服务账户、资源定额等,是集群中所有资源对象的自动化控制中心。
负责确保 Kubernetes 系统的实际状态收敛到所需状态,默认提供了一些控制器,例如 DeploymentControllers 控制器、StatefulSet 控制器、Namespace 控制器及 PersistentVolume 控制器等,每个控制器通过 kube-apiserver 组件提供的接口实时监控整个集群每个资源对象的当前状态。
作为控制节点,基于 Etcd 集群上的分布式锁实现领导者选举机制,保证高可用。通过 kube-apiserver 提供的资源锁进行选举竞争,抢先获取锁的实例被称为 Leader 节点,并运行主逻辑;而未获取锁的实例被称为 Candidate 节点,运行时处于阻塞状态。
kube-scheduler:负责在 Kubernetes 集群中为一个 Pod 资源对象找到合适的节点并在该节点上运行,组件监控整个集群的 Pod 资源对象和 Node 资源对象,当监控到新的 Pod 资源对象时,会通过调度算法为其选择最优节点。
调度算法分为两种,预选调度算法和优选调度算法。
预选策略输入是所有节点,输出是满足预选条件的节点。调度器会同时开启多个协程并发进行 Predicates 过滤,每个协程按照固定的顺序进行过滤,最后返回过滤后可以运行 Pod 的 Node 列表。
GeneralPredicates 规则 最基础的调度策略,这个接口也会被其它组件直接调用,比如 kubelet 在启动 Pod 前会再执行一遍 GeneralPredicates 用于二次确认。
Volume 规则 负责与容器持久化 Volume 相关的调度策略。
Node 规则 负责检查待调度 Pod 是否满足 Node 本身的一些条件。
Pod 规则 负责检查待调度 Pod 与 Node 上已有 Pod 之间的亲和性关系。
优选策略通过前面预选策略过滤出来的 Node 列表,会再一次使用优选策略为这些 Node 打分,最终得分最高的 Node 会作为该 Pod 的调度对象。
总分 = (打分函数1 权重1) +(打分函数2 权重2) + ... + (打分函数3 * 权重3)
打分函数的打分范围为 [0, 10] 分,0 表示非常不合适,10 表示非常合适。每个打分函数都可以配置对应的权重,默认权重值为 1,如果某个打分函数特别重要就可以增加该权重值。
除调度策略外,Kubernetes还支持优先级调度、抢占机制及亲和性调度等功能。
1.2 Worker
客户端也被称为工作节点,它在集群中主要负责如下任务。
负责管理所有容器(Container)。
负责监控、上报所有 Pod 的运行状态。
其中,也主要包含三个组件:
kubelet 组件:负责接收、处理、上报 kube-apiserver 组件下发的任务,启动时会向 kube-apiserver 注册节点自身信息,管理例如 Pod 资源对象的创建、修改、监控、删除、驱逐及 Pod 生命周期管理等。
kubelet 组件实现了3种开放接口:
容器运行时接口、容器网络接口、容器存储接口。Container Runtime Interface:简称 CRI,提供容器运行时通用插件接口服务,定义了容器和镜像服务的接口,将 kubelet 组件与容器运行时进行解耦,将原来完全面向 Pod 级别的内部接口拆分成面向 Sandbox 和 Container 的 gRPC 接口,并将镜像管理和容器管理分离给不同的服务。
Container Network Interface:简称 CNI,提供网络通用插件接口服务,定义了 Kubernetes 网络插件的基础,容器创建时通过 CNI 插件配置网络。
Container Storage Interface:简称 CSI,提供存储通用插件接口服务,定义了容器存储卷标准规范,容器创建时通过 CSI 插件配置存储卷。
kube-proxy 组件:作为节点上的网络代理,运行在每个 Kubernetes 节点上。它监控 kube-apiserver 的服务和端点资源变化,并通过 iptables/ipvs 等配置负载均衡器,为一组 Pod 提供统一的 TCP/UDP 流量转发和负载均衡功能。
该组件是参与管理 Pod-to-Service 和 External-to-Service 网络的最重要的节点组件之一,作用相当于代理模型,对于某个
IP:Port的请求,负责将其转发给专用网络上的相应服务或应用程序。但是,kube-proxy 组件与其他负载均衡服务的区别在于,kube-proxy 代理只向 Kubernetes 服务及其后端 Pod 发出请求。container 组件:负责容器的基础管理服务,接收kubelet组件的指令。
2、Kubernetes Project Layout 设计
main 结构中定义了进程运行的周期,包括从进程启动、运行到退出的过程。以 kube-apiserver 组件为例,初始化过程如下所示:
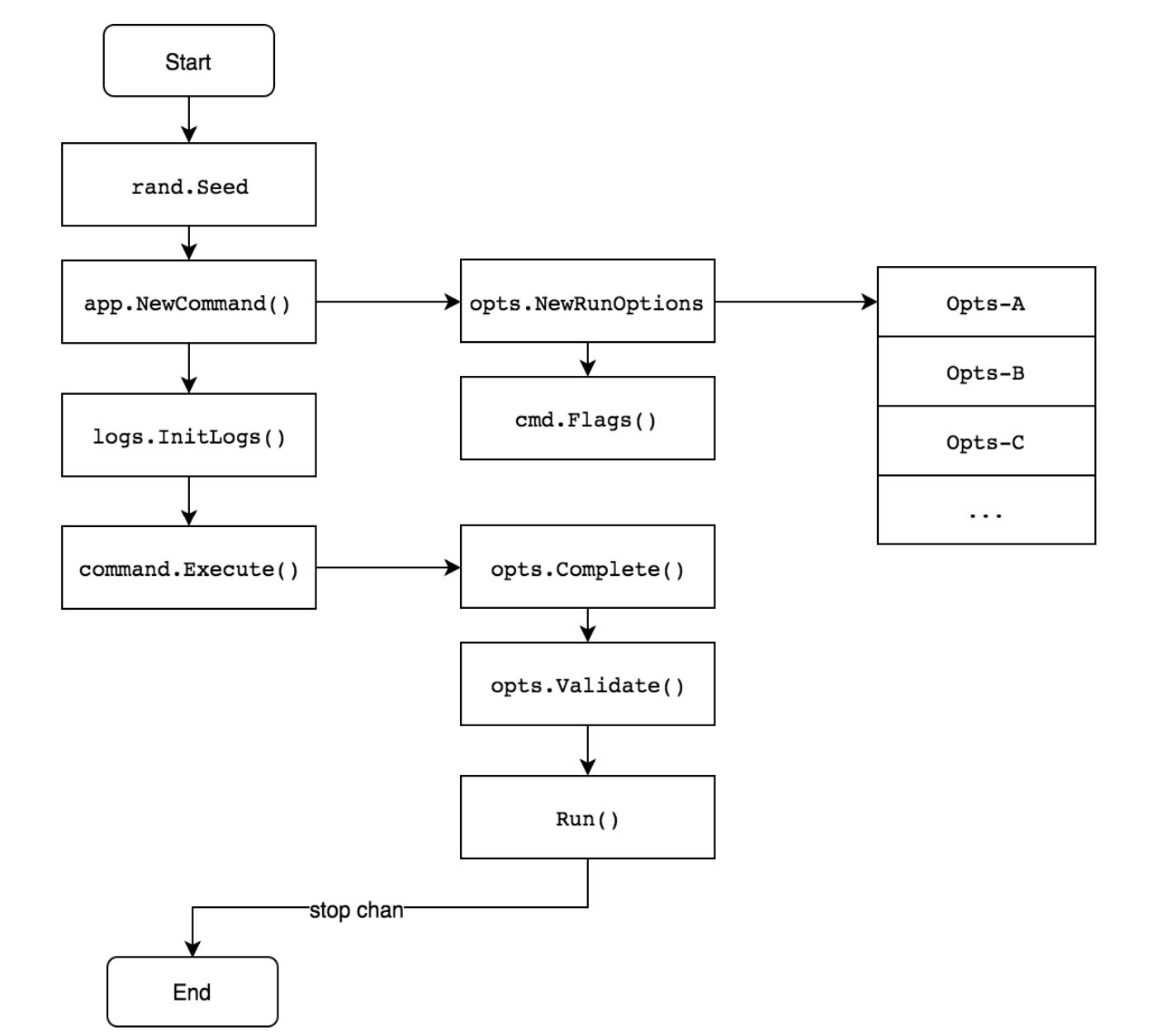
rand.Seed:组件中的全局随机数生成对象;
app.NewCommand:实例化命令行参数。通过 flags 对命令行参数进行解析并存储至 Options 对象中;
logs.InitLogs:实例化日志对象,用于日志管理;
command.Execute:组件进程运行的逻辑。运行前通过 Complete 函数填充默认参数,通过 Validate 函数验证所有参数,最后通过 Run 函数持久运行。只有当进程收到退出信号时,进程才会退出。
- 感谢你赐予我前进的力量
-
微信
- 支付宝